Добьёмся успеха вместе!
науке.by
первый белорусский
портал молодых ученых
Поиск тегов
Найдено на страницах
-
Занятие 2. Построение графика распределения. Построение гистограммы
Разделы: Школа молодого ученого / Основы доказательной медицины. Биомедицинская статистика.
Теги: Statistika 6.0, Медицинская Статистика, СтатистикаПОСТРОЕНИЕ ГРАФИКА РАСПРЕДЕЛЕНИЯ
В программе STATISTICA реализован графически-ориентированный подход к анализу данных. Он заключается в том, чтобы получать всестороннее визуальное представление данных на всех этапах статистической обработки. В связи с этим программа обладает огромным набором различных типов графиков, которые можно построить, обратившись к пункту главного меню Graphs (рисунок ниже) или к соответствующим закладкам того или иного статистического модуля.

Выбор типа графика в программе STATISTICA.
Для того чтобы программа смогла построить график распределения, из данных столбца «Лейкоциты» нужно сформировать вариационный ряд, т.е. в двойной ряд чисел, в котором содержатся значения анализируемого признака и частоты их встречаемости в выборке. Перед тем как сделать это, добавим два столбца в таблицу Spreadsheet, содержащую данные о числе лейкоцитов. Подведите курсор к заголовку столбца «Лейкоциты» и нажмите правую клавишу мыши. В выскочившем контекстном меню выберите пункт Add Variables (добавить переменные). Появится диалоговое окно, в котором нужно указать, сколько переменных мы намерены добавить (поле How Many: выставляем 2) и после какой из существующих переменных их нужно вставить (поле After: наберите слово «Лейкоциты»). Остальные настройки установите так, как это показано на рисунке Диалоговое окно «Add Variables». В таблице появятся два новых столбца с названиями «NewVar1» и «NewVar2». Переименуйте их в «Количество лейкоцитов» и «Количество пациентов» соответственно (о том, как задать имя переменной, рассказано выше).

Диалоговое окно «Add Variables»
Теперь построим вариационный ряд. Для этого в пункте основного меню Statistics (Статистические процедуры) выберем модуль Basic Statistics/Tables (Основные статистические показатели/Таблицы), а в нем - опцию Frequency Tables (Таблицы частот). В появившемся диалоговом окне программе необходимо указать, какую именно переменную мы собираемся анализировать. Для этого служит кнопка Variables (переменные) (рисунок ниже). При нажатии на нее всплывает еще одно окошко (Select the variables for the analysis), основная часть которого занята списком переменных, имеющихся в таблице Spreadsheet. Дважды кликните по пункту «Лейкоциты», а затем нажмите либо кнопку Summary: Frequency Tables (Результат: Частотные таблицы), либо Summary (Результат), либо просто клавишу «Ввод» на клавиатуре.

Выбор переменной для анализа Frequency Tables
В итоге программа выдаст таблицу, представляющую собой «расширенный» вариант вариационного ряда. В этой таблице имеются следующие столбцы:
- Category (Категория): содержит ранжированные численные значения анализируемой переменной, отмеченные в выборке. В случае с нашим примером видим, что количество лейкоцитов у пациентов изменялось от 6,4 до 27.
- Count (Счет): здесь приведены частоты, с которыми в выборке встречались те или иные значения переменной (так, в ходе исследования обнаружено, что уровень лейкоцитов 6,4 был у 1 пациента, 21,4 у 4 пациентов, а 11,6 у 3 пациентов и т.д.).
- Cumulative count: накопленные частоты численных значений переменной.
- Percent: процентная доля, которую составляет каждая из частот от общего числа наблюдений.
- Cumulative percent: накопленные процентные доли частот.
Последняя строка итоговой таблицы называется Missing (Отсутствующие) - она имеет отношение к пропущенным (т.е. не внесенным в таблицу) значениям анализируемой переменной. Таковых в нашем примере нет, в связи с чем, на пересечении столбца Count и строки Missing видим 0.
Рассмотрите внимательно: итоговая таблица анализа Frequency Tables является частью окна с заголовком Workbook (рабочая книга). Такая форма вывода результатов очень удобна и является характерной особенностью программы STATISTICA. Результаты любого анализа, который в дальнейшем применялся бы к данным открытого в текущий момент файла, заносился бы в эту же рабочую книгу на отдельный лист. Структура рабочей книги (= каталог выполненных анализов) отображается в специальном окошке слева. Рабочую книгу можно сохранить в виде самостоятельного файла (с расширением .stw) и при необходимости вернуться к ней в любое время.
Рабочая книга, содержащая результат анализа Frequency Tables.
Для построения графика распределения нам потребуются числа из столбцов Category и Count, которые необходимо будет перенести из итоговой таблицы анализа Frequency Tables в таблицу Spreadsheet. Чтобы скопировать данные из столбца Category, выполните следующие действия:
- Подведите курсор к первой ячейке столбца Category, нажмите левую кнопку мыши и, удерживая ее, доведите курсор до предпоследней ячейки этого же столбца. При этом выделятся все ячейки таблицы (за исключением строки Missing). Все они нам не нужны, поэтому...
- Нажмите правую кнопку мыши и из появившегося контекстного меню выберите пункт Select case names only (Выбрать только имена наблюдений), находящийся в самом верху списка.
- Примените сочетание клавиш Ctrl+C.
- Установите курсор в первую ячейку столбца «Количество лейкоцитов» таблицы Spreadsheet.
- Примените сочетание клавиш Ctrl+V. Готово!
!! Данные из столбца Count итоговой таблицы анализа Frequency tables легко выделяются, копируются (Ctrl+C) и вставляются в столбец «Количество пациентов» обычным способом (Ctrl+V), в чем вы можете убедиться сами... В результате описанных операций по переносу данных таблица Spreadsheet должна принять вид, подобный приведенному на рисунке.

Результат копирования и переноса данных из столбцов Category и Count итоговой таблицы Frequency Tables в таблицу Spreadsheet
Теперь у нас есть все необходимое, чтобы построить полигон распределения по данным о количестве лейкоцитов у пациентов с перитонитом. В пункте главного меню Graphs (Графики) выберите подпункт 2D Graphs (двухмерные графики), а в нем - опцию Line Plots (Variables) (линейные графики (по переменным)). В появившемся диалоговом окне выберите закладку Advanced (расширенные настройки). На ней в поле Graph Type (Тип графика) выделите XY Trace, а в выпадающем меню Display points (отображать точки) выберите On (Включить). Наконец откройте закладку Options 1, разыщите на ней выпадающее меню Case labels (Подписи наблюдений) и выберите пункт Off (Отключить).

Окно 2D Line Plots на закладке Advanced
Теперь программе необходимо указать, в каком из столбцов таблицы Spreadsheet находятся данные о количестве лейкоцитов (ось X), а в каком - данные о частотах встречаемости (ось Y). Для этого снова возвращаемся на закладку Advanced и нажимаем кнопку Variables (переменные). Появится окошко с двумя списками переменных. В левом списке выделяем пункт «Количество лейкоцитов», а в правом - пункт «Количество пациентов». Жмем ОК, затем еще раз ОК и получаем график. Заметьте: график является составной частью рабочей книги Workbook, как это ранее было с итоговой таблицей анализа Frequency Tables.

График распределения, построенный с помощью программы STATISTICA
Если кликнуть один раз по любой части получившегося графика правой кнопкой мыши и из контекстного меню выбрать пункт Copy Graph, можно скопировать его в буфер обмена и затем вставить в документ какого-либо другого Windows-приложения, например, MS Word или Excel. График можно сохранить также как самостоятельный файл (с расширением .stg). Для этого необходимо выделить иконку графика в каталоге рабочей книги и, удерживая нажатой левую клавишу мыши, перетащить ее за пределы рабочей книги. В результате график окажется в отдельном окошке. Теперь, кликнув по нему правой кнопкой мыши, можно применить команду Save Graph (сохранить график).
Процедура, предшествующая сохранению графика в виде самостоятельного файла.
Программа STATISTICA предоставляет огромные возможности для придания графику необходимого внешнего вида. Достаточно кликнуть по интересующему вас элементу, и появится окошко со множеством опций по его преобразованию (заголовок, оси и их названия, маркеры, их форма, цвет и размер, и т.п.).
ПОСТРОЕНИЕ ГИСТОГРАММЫ
Ниже представлены данные о температуре тела пациентов с перитонитом (в °С):
Размах значений температуры тела составляет 38,6 – 35,3 = 3,3. Для графического изображения частотного распределения в данном случае лучше подходит гистограмма, а не график распределения.
Откройте файл «Распределение.sta» и добавьте в него еще одну переменную после столбца «Количество пациента» (как это сделать см. выше) и назовите ее «температура». Введите в этот новый столбец данные о температуре тела пациентов. Далее для построения гистограммы выполните следующие действия:
В основном меню Graphs выберите 2D Graphs > Histograms (Гистограммы).
В появившемся окне выберите закладку Advanced. Нажав на кнопку Variables, выберите для анализа переменную «Температура». В поле Fit type (Тип подгонки) выберите Off, а в выпадающем меню Y axis (Ось Y) - %. Остальные настройки оставьте без изменений.
Нажмите кнопку OK. В результате у вас должен получиться график, подобный приведенному на рисунке:
 Гистограмма, построенная с помощью программы STATISTICA.
Гистограмма, построенная с помощью программы STATISTICA.laquo;Распределение.sta
-
Занятие 3. Описательная статистика
Разделы: Школа молодого ученого / Основы доказательной медицины. Биомедицинская статистика.
Теги: Statistika 6.0, Медицинская Статистика, Описательная СтатистикаЗанятие 3.
ОПИСАТЕЛЬНАЯ СТАТИСТИКА
Расчет параметров описательной статистики в программе STATISTICA выполняется при помощи модуля Descriptive statistics (Описательная статистика).
Для удобства работы можно вывести дополнительную панель инструментов, которая содержит кнопки запуска практически всех типов статистического анализа, реализованных в программе. Вывод этой панели значительно облегчает работу, поскольку позволяет оперативно вызывать требуемый анализ. Для этого в разделе View (Вид) основного меню выберите пункт Toolbars (Инструменты), а в нем - Statistics. В верхней части рабочего окна появится данная дополнительная панель.
Откройте файл с данными или создайте новый.
Войдите в раздел Statistics основного меню и выберите в нем пункт Basic statistics/Tables. В выскочившем окошке выберите пункт Descriptive statistics (Описательная статистика).
Внешний вид окна Descriptive statistics приведен на рисунке 1.

Рисунок 1. Внешний вид модуля Descriptive statistics на закладке Quick
Окно Descriptive statistics имеет некоторые элементы, встречающиеся в большинстве модулей программы, например:
- кнопка Variables, с помощью которой программе указываются анализируемые переменные;
- кнопка Summary - для вывода результатов анализа;
- кнопка Options - для настройки внешнего вида программы и окон вывода результатов анализа;
- кнопка Cancel – отмена.
Кроме того, это окно имеет несколько закладок.
По умолчанию перед пользователем первой предстает закладка Quick (Быстро). Находясь на ней, можно выполнить следующие операции:
- рассчитать показатели описательной статистики - кнопка Summary: Descriptive statistics. Перечень рассчитываемых показателей определяется настройками, заданными на другой закладке окна - Advanced;
- получить таблицу с частотами встречаемости каждого из значений анализируемой переменной - кнопка Frequency Tables (см. занятие 1);
- построить гистограмму частотного распределения значений анализируемой переменной - кнопка Histograms. Автоматически вместе с гистограммой программа нарисует теоретически ожидаемую нормальную кривую, глядя на которую, можно сделать вывод о том, подчиняются ли анализируемые данные нормальному закону распределения.
- Построить для выбранной переменной (или для нескольких переменных одновременно) график типа “коробочка с усами” (см. ниже) - кнопка Box & whisker plot for all variables.
Для расчета подробного перечня показателей описательной статистики следует воспользоваться другой закладкой модуля – Advanced (Расширенные настройки).

Рисунок 2. Окно Descriptive statistics на закладке Advanced (Расширенные настройки)
Основную часть закладки Advanced занимает список следующих статистических показателей:
- Valid N - объем совокупности;
- Mean - арифметическая средняя;
- Sum - сумма значений анализируемой переменной;
- Median - медиана;
- Mode - мода;
- Geom. mean - геометрическая средняя;
- Harm. mean - гармоническая средняя;
- Standard Deviation - стандартное отклонение;
- Variance - дисперсия;
- Std. err. of mean - стандартная ошибка средней;
- Conf. limits for means: Interval % - доверительные пределы для средних: ширина доверительного интервала;
- Skewness - коэффициент асимметрии;
- Std. err., Skewness - стандартная ошибка коэффциента асимметрии;
- Kurtosis - коэффициент эксцесса;
- Std. err., Kurtosis - стандартная ошибка коэффициента эксцесса;
- Minimum & maximum - минимальное и максимальное значения;
- Lower & upper quartiles - нижний и верхний квартили;
- Perсentile boundaries: First & Second: первый и второй процентили;
- Range - размах;
- Quartile range - межквартильный размах.
На закладке Advanced имеются также следующие кнопки:
- select all stats - нажатие на эту кнопку приводит к выбору всех имеющихся статистических показателей для последующего их расчета;
- reset - сброс всех показателей;
- save settings as default - выбрав определенные показатели и нажав на эту кнопку, вы даете программе команду, чтобы она рассматривала данные показатели в качестве стандартных при последующих запусках модуля.
Следующей за Advanced идет закладка Normality (Нормальность).

Рисунок 3. Окно Descriptive statistics на закладке Normality
Это важная составляющая модуля описательной статистики, которой вам придется пользоваться очень часто. С помощью элементов этой закладки можно определить, насколько статистически значимо частотное распределение ваших данных отличается от нормального распределения. Наиболее важными элементами здесь являются:
- кнопки Frequency tables и Histograms;
- поле Categorization (Категоризация): воспользовавшись опцией Number of intervals, можно указать программе, сколько “столбиков” ей следует изобразить на гистограмме. Эта опция используется в тех случаях, когда анализируемый биологический признак является непрерывным. Если же он дискретен, т.е. выражается только целыми числами, следует отметить опцию Integral intervals (Categories).
- опция Normal expected frequencies (Ожидаемые нормальные частоты): при ее выделении и последующем нажатии на кнопку Frequency tables программа выдаст таблицу, которая помимо фактических частот численных значений переменной, будет содержать также теоретически ожидаемые нормальные частоты.
Тесты, применяемые для проверки соответствия анализируемых данных закону нормального распределения - Kolmogorov-Smirnov & Lilliefors test for normality и Shapiro-Wilk’s W test. Подробнее эти методы будут рассмотрены позже.
В ряде случаев полезной может оказаться и закладка Prob. & Scatterplots (Вероятностные графики и диаграммы рассеяния), следующая за Normality. В частности, с ее помощью можно построить двух- и трехмерные графики зависимости между двумя переменными, а также проверить данные на нормальность с использованием т.н. «вероятностной бумаги» (Normal probability plot).
-
Занятие 4. Построение графика Whisker plot
Разделы: Школа молодого ученого / Основы доказательной медицины. Биомедицинская статистика.
Теги: Statistika 6.0, Whisker Plot “График С Усами”, Медицинская СтатистикаЗанятие 4
Построение графика Whisker plot
"График с усами"
Графики данного типа применяются для описания временной динамики или пространственного градиента той или иной переменной. Точки на них чаще всего соответствуют средней арифметической или, реже, медиане изучаемого признака в некоторый момент времени или в определенном участке пространства. Отличительной особенностью является наличие у точек т.н. «усов» (whiskers) - вертикально отходящих линий, длина которых соответствует величине выбранного исследователем показателя разброса данных (минимум и максимум, стандартное отклонение, дисперсия, квартили) или точности оценки генеральных параметров (стандартная ошибка, доверительный интервал).
Пример:
В течение 7 дней пациенту измеряли температуру тела. Измерения проводились 4 раза в день (каждые 6 часов). Полученные данные приведены на рисунке 1. Необходимо изобразить графически динамику среднесуточного колебания температуры тела.

Рисунок 1. Таблица данных для построения «графика с усами»
Обратите внимание на то, как данные внесены в таблицу Spreadsheet «Температура тела»! Чтобы программа «поняла», какие из них относятся к какому дню пребывания в стационаре, был введен дополнительный столбец «Сутки». В нем перечислены номера суток, во время которых выполнялись измерения, а в соседнем столбце – «Температура» - приведены сами значения исследуемой переменной.
Столбец «Сутки» в терминах программы называется группирующей переменной (Grouping variable), а столбец, в котором непосредственно находятся значения исследуемого признака - зависимой переменной (Dependent variable).
Для построения «графика с усами» необходимо в разделе Graphs основного меню выбрать 2D Graphs, а затем - Means w/Error plots (Графики средних с ошибками). Вешний вид этого окна представлен на рисунке 2.

Рисунок 2.Выбор из меню графика Whisker plot

Рисунок 3. Окно Means with error plots на закладке Quick
Как всегда, начинать следует с указания программе переменных, которые будут участвовать в анализе. Нажимаем кнопку Variables. Появится окошко (Select variables for means with error plots) с двумя списками имеющихся в таблице переменных. В левом списке необходимо выбрать зависимую переменную. В нашем случае это, как вы помните, «Температура». В правом списке выбираем группирующую переменную – «Сутки», и жмем ОК.

Рисунок 4. Выбор зависимой и группирующей переменной
Далее в поле Grouping intervals (Группирующие интервалы) нужно указать программе, на какие интервалы ей следует разбить ось Х. В нашем примере вдоль оси Х должны располагаться номера суток. Чтобы программа «поняла» это, нажимаем кнопку Codes (Коды), а в появляющемся окошке - кнопки All (Все) и ОК. Пояснение: в качестве кодов в нашем примере выступают номера суток. Поскольку мы хотим, чтобы на графике были отображены данные для всех суток, в течение которых выполнялись измерения температуры, нажимается кнопка All.

Рисунок 5. Выбор группирующих интервалов
Осталось указать программе, чему на графике будут соответствовать «усы», отходящие от точек. Для этого служит поле Whisker (Ус). Предположим, мы хотим, чтобы длина усов в каждую из сторон относительно точки была равна одному стандартному отклонению. В выпадающем меню Value (Величина) выбираем Std dev (Стандартное отклонение), а в поле Coefficient (Коэффициент) ставим 1.
Теперь все настройки завершены. Нажимаем ОК и получаемый долгожданный «График с усами».

Рисунок 6. «График с усами», построенный программой STATISTICA
-
Занятие 5. Построение графика Box-whisker plot
Разделы: Школа молодого ученого / Основы доказательной медицины. Биомедицинская статистика.
Теги: Box Whisker Plot, Statistika 6.0, График, Медицинская СтатистикаЗанятие 5
Построение графика Box-whisker plot (коробчатая диаграмма, «Ящик с усами»)
Графики типа Box-whisker plot - коробчатые диаграммы - «Ящик с усами» - получили свое название за характерный вид: точку, соответствующую средней арифметической или медиане, окружает вертикально расположенный прямоугольник («ящик»), длина которого равна одному из показателей разброса или точности оценки генерального параметра. Дополнительно от этого прямоугольника отходят «усы», также равные по длине одному из показателей разброса или точности. Таким образом, графики Box-whisker plot позволяют показать срединные значения (среднее арифметическое, медиана) и значения разброса в выборке. Такие графики обычно используются для визуальной оценки разницы между двумя или более выборками (например, между датами отбора проб, экспериментальными группами и т.д.).
Для построения «ящиков с усами» необходимо в разделе Graphs основного меню выбрать 2D Graphs, а затем - Box plots.

Рисунок 1. Выбор в разделе Graphs основного меню Box-whisker plot
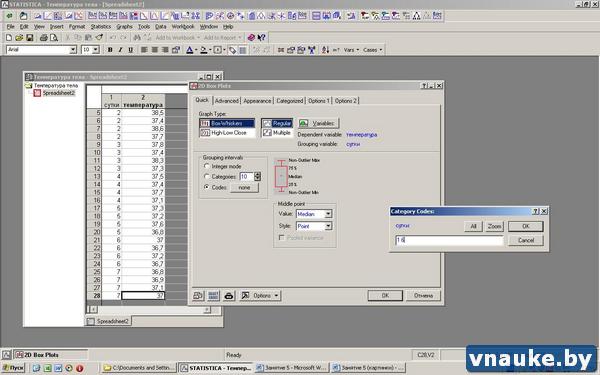
Рисунок 2. Внешний вид данного модуля, открытый на закладке Quick
Вернемся к примеру, рассмотренному на предыдущем занятии. Предположим, что мы хотим визуально сравнить, различается ли среднесуточная температура тела в 1-ые и 6-ые сутки. Для построения графика Box-whisker plot необходимо установить следующие настройки:
- На закладке Advanced нажать на кнопку Variables и указать, какая из переменных является зависимой (Dependent) («Температура»), а какая - группирующей (Grouping) («Сутки»).
- В поле Grouping intervals выбрать опцию Codes, а затем нажать кнопку Specify codes (Определить коды), чтобы указать программе, какие именно месяцы будут участвовать в построении графика. В выскочившем окошке ввести через пробел слова «1-ые» и «6-ые».
- В меню Value поля Middle point (Средняя точка) необходимо выбрать Mean (Средняя) или Median (Медиана). В результате программа будет «знать», что на графике в качестве точек ей следует изображать средние значения температуры или ее медианы, соответственно. Например, выбираем Mean. Чуть выше расположенный в окне график изменяется и мы видим, как именно будут представлены наши данные на график. В данном случае это средняя ошибка и стандартное отклонение.
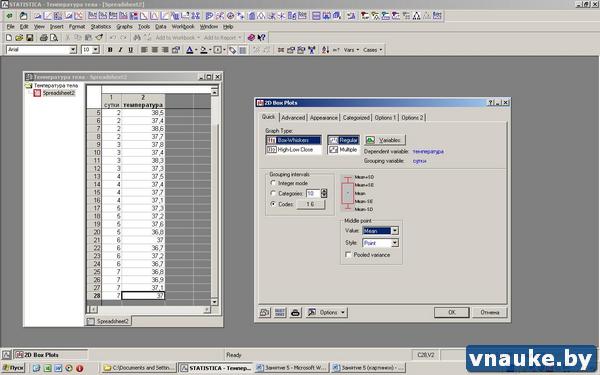
Рисунок 3. Порядок действий для построения графика Box-whisker plot
Теперь все настройки завершены. Нажимаем ОК и получаемый долгожданный «Ящикс усами».
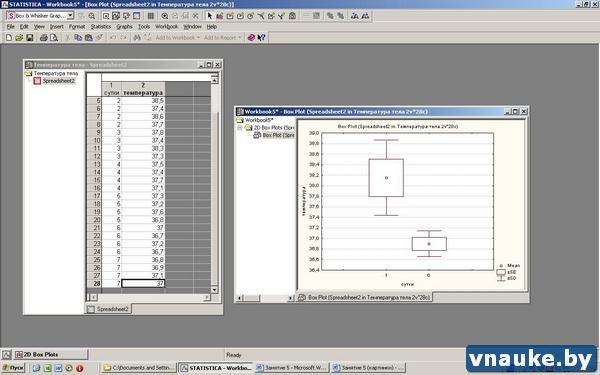
Рисунок 4. График типа Box-whisker plot - «Ящик с усами»
 Google+
Google+